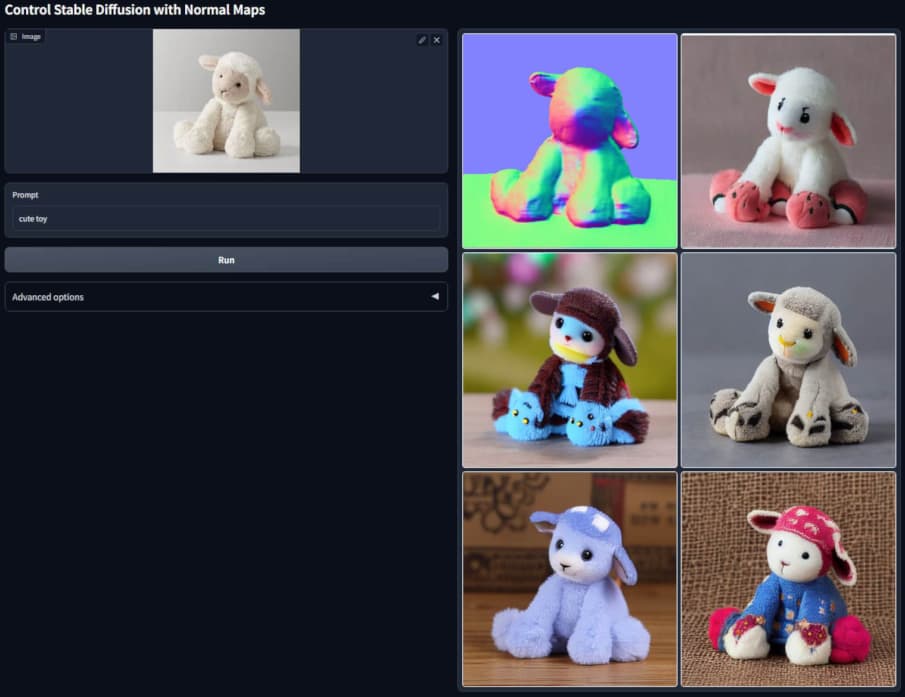
Enhancing Stable Diffusion Models with
Online. Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input, cultivates autonomous freedom to produce incredible imagery, empowers billions of people to create stunning art within seconds. Create beautiful art using stable diffusion ONLINE for free.

A Complete Guide to Stable Diffusion for Beginners
Stable Diffusion consists of three parts: A text encoder, which turns your prompt into a latent vector. A diffusion model, which repeatedly "denoises" a 64x64 latent image patch. A decoder, which turns the final 64x64 latent patch into a higher-resolution 512x512 image. First, your text prompt gets projected into a latent vector space by the.
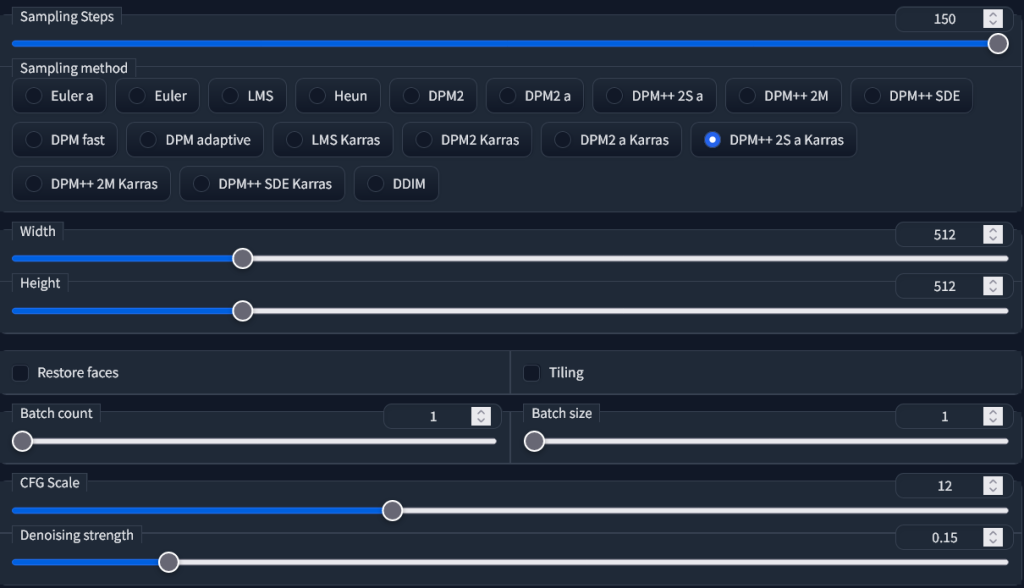
How to Upscale Images With Stable Diffusion Easy With AI
Stable Diffusion v1.5. Stable Diffusion v1.5 is a latent diffusion model initialized from an earlier checkpoint, and further finetuned for 595K steps on 512x512 images. To use this pipeline for image-to-image, you'll need to prepare an initial image to pass to the pipeline.

Stable Diffusion tutorial Textguided imagetoimage generation with Stable Diffusion tutorial
Running the Diffusion Process. With your images prepared and settings configured, it's time to run the stable diffusion process using Img2Img. Here's a step-by-step guide: Load your images: Import your input images into the Img2Img model, ensuring they're properly preprocessed and compatible with the model architecture.

The Illustrated Stable Diffusion Jay Alammar Visualizing machine learning one concept at a time.
Apply the filter: Apply the stable diffusion filter to your image and observe the results. Iterate if necessary: If the results are not satisfactory, adjust the filter parameters or try a different filter. Repeat the process until you achieve the desired outcome. After applying stable diffusion techniques with img2img, it's important to.

Stable Diffusion, a milestone?
Stable Diffusion is a Latent Diffusion model developed by researchers from the Machine Vision and Learning group at LMU Munich, a.k.a CompVis.. When running *Stable Diffusion* in inference, we usually want to generate a certain type, or style of image and then improve upon it. Improving upon a previously generated image means running.

Tutorial Stable Diffusion Art
Stable Diffusion is a deep learning, text-to-image model released in 2022 based on diffusion techniques. It is considered to be a part of the ongoing artifical intelligence boom.. It is primarily used to generate detailed images conditioned on text descriptions, though it can also be applied to other tasks such as inpainting, outpainting, and generating image-to-image translations guided by a.

Stable Diffusion tutorial How to make videos with Stable Diffusion? Interpolation
The first step to implement our Stable Diffusion Image-to-Image Pipeline is to install the necessary libraries. To do so, we use pip to install the following libraries: transformers, diffusers, accelerate, torch, ipywidgets, ftfy. !pip install -q transformers diffusers accelerate torch==1.13.1.

How to stylize images using Stable Diffusion AI Stable Diffusion Art
This only applies to image-to-image and inpainting generations. It determines how much of your original image will be changed to match the given prompt. Higher numbers change more of the image, lower numbers keep the original image intact. Values between 0.5 and 0.75 give a good balance. When inpainting, setting the prompt strength to 1 will.

How to cartoonize photo with Stable Diffusion Stable Diffusion Art
To run Stable Diffusion locally on your PC, download Stable Diffusion from GitHub and the latest checkpoints from HuggingFace.co, and install them. Then run Stable Diffusion in a special python environment using Miniconda. Artificial Intelligence (AI) art is currently all the rage, but most AI image generators run in the cloud. Stable Diffusion.

Generating images with Stable Diffusion
Stable Diffusion web UI is a browser interface based on the Gradio library for Stable Diffusion. It provides a user-friendly way to interact with Stable Diffusion, an open-source text-to-image generation model. The web UI offers various features, including generating images from text prompts (txt2img), image-to-image processing (img2img.

What is Stable Diffusion and How Does it Work?
Head to the prompt collection, pick an image you like, and steal the prompt! The downside is that you may not understand why it generates high-quality images. Read the notes and change the prompt to see the effect. Alternatively, use image collection sites like PlaygroundAI. Pick an image you like and remix the prompt.

Stable Diffusion prompt a definitive guide Stable Diffusion Art
Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities. While the model is not yet broadly available, today, we are opening the waitlist for an early preview.

Stable Diffusion with 🧨 Diffusers
Image-to-image. The Stable Diffusion model can also be applied to image-to-image generation by passing a text prompt and an initial image to condition the generation of new images. The StableDiffusionImg2ImgPipeline uses the diffusion-denoising mechanism proposed in SDEdit:.
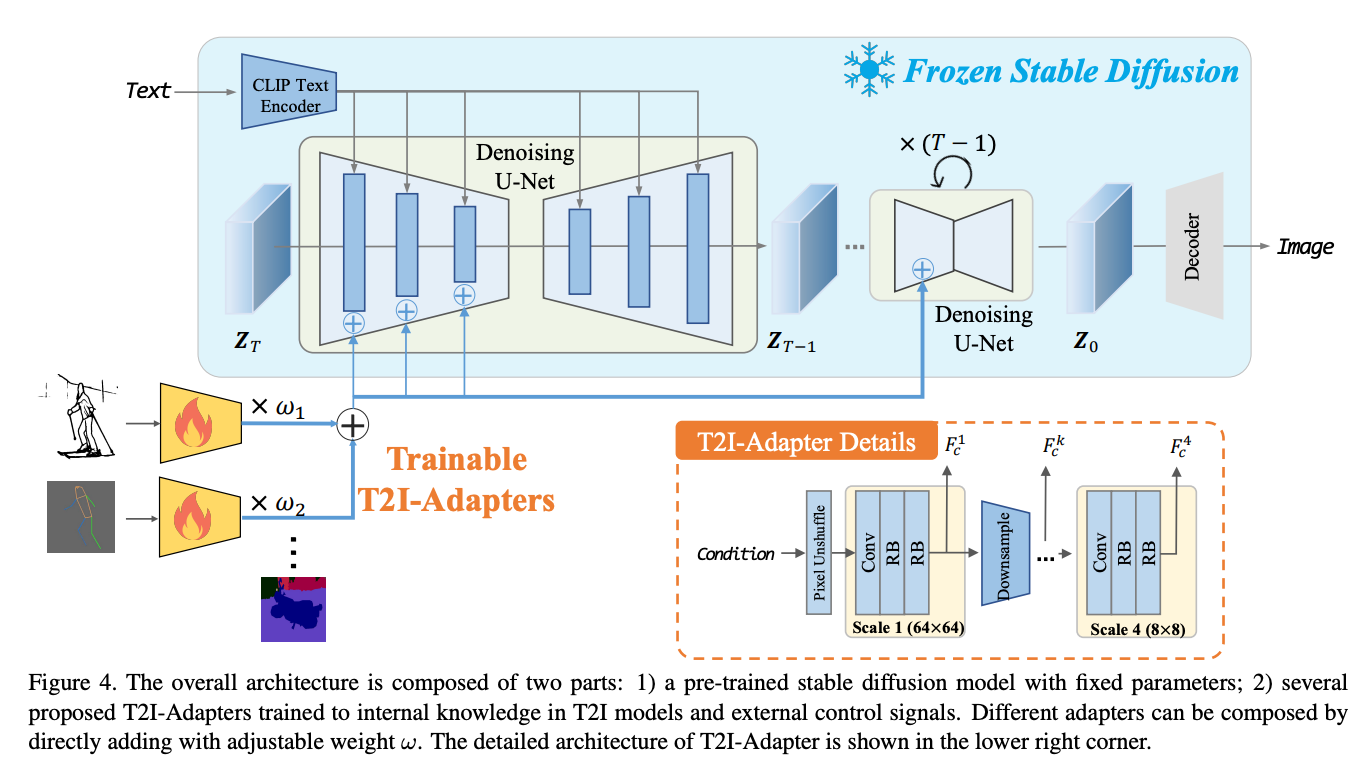
What Stable Diffusion Techniques belong in your Image Synthesis workflow? Part 1
The Stable Diffusion 3 AI image generator is a innovative tool that empowers creators to push the boundaries of visual content creation. Its advanced capabilities, coupled with its user-friendly.
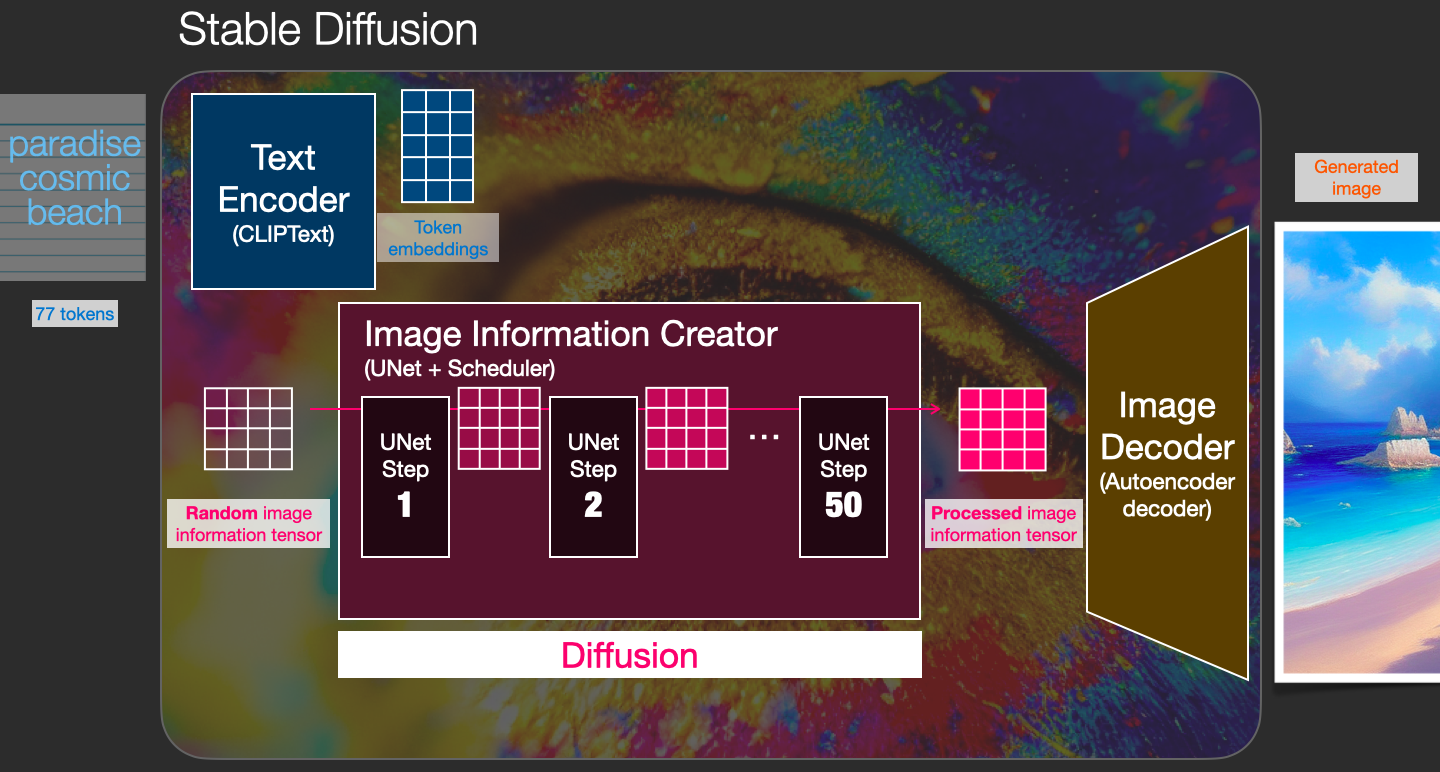
The Illustrated Stable Diffusion Jay Alammar Visualizing machine learning one concept at a time.
Stable Diffusion is a generative artificial intelligence (generative AI) model that produces unique photorealistic images from text and image prompts. It originally launched in 2022. Besides images, you can also use the model to create videos and animations. The model is based on diffusion technology and uses latent space.
- Marilyn Manson Album Antichrist Superstar
- Cathedral Church Of St John The Divine Nyc
- Iga Local Grocer Armadale Photos
- Mya Tiger At Hotel Esplanade
- Average Car Kilometers Per Year
- Is Michelle Obama A Man
- Cold Sore 3 Tablets One Dose Australia
- Things To Do In Portofino
- 28 Degrees Currency Conversion Rate
- Paddington Bear Costume For Adults